COCO-GAN: Generation by Parts via Conditional Coordinating
Chieh Hubert Lin Chia-Che Chang Yu-Sheng Chen Da-Cheng Juan Wei Wei Hwann-Tzong Chen
National Tsing Hua University National Taiwan University Google AI
in ICCV 2019 (Oral)
Paper (Arxiv) | Paper (Full Resolution) | Blog (Medium) | Code (TensorFlow)


|

|
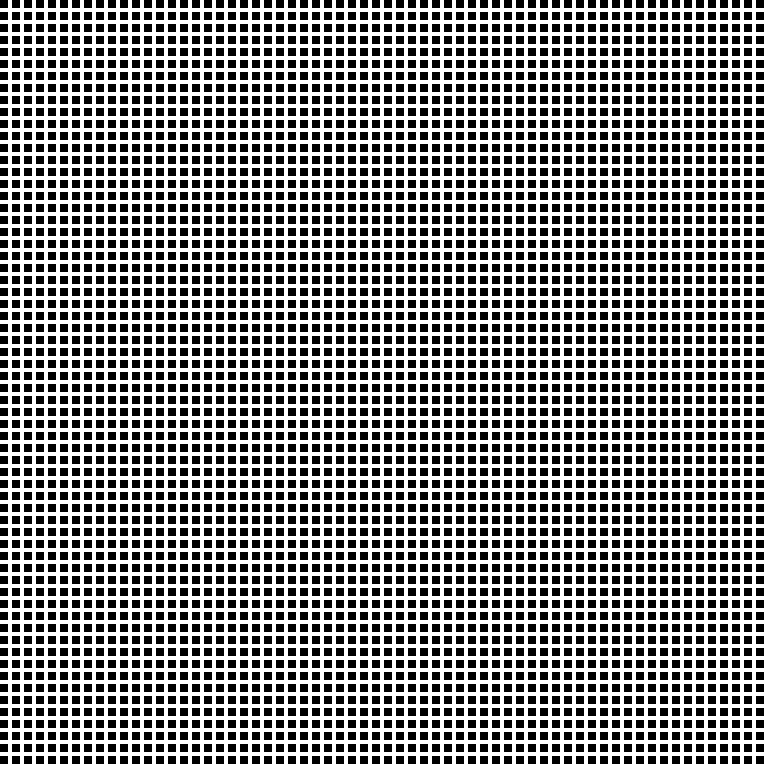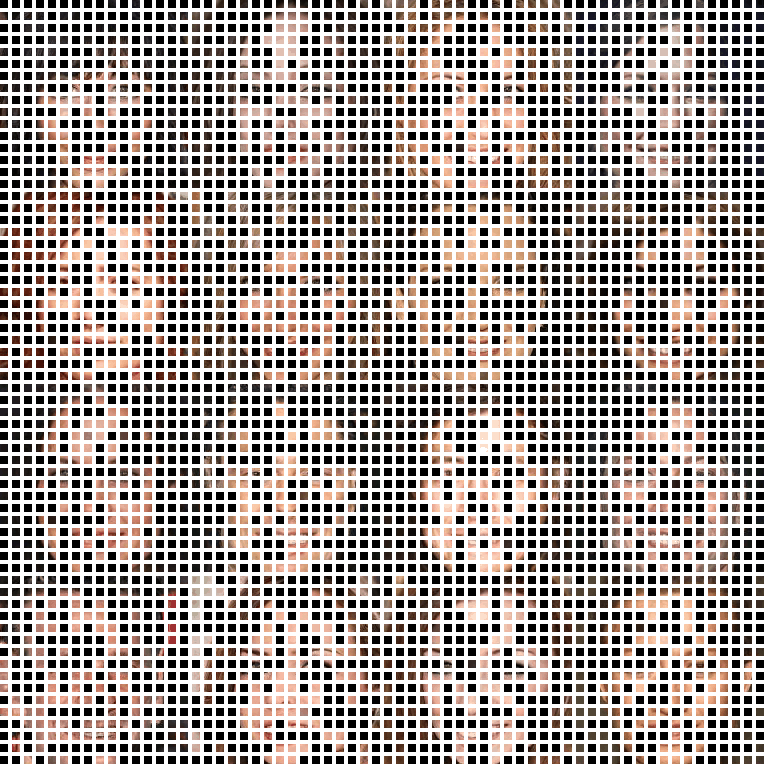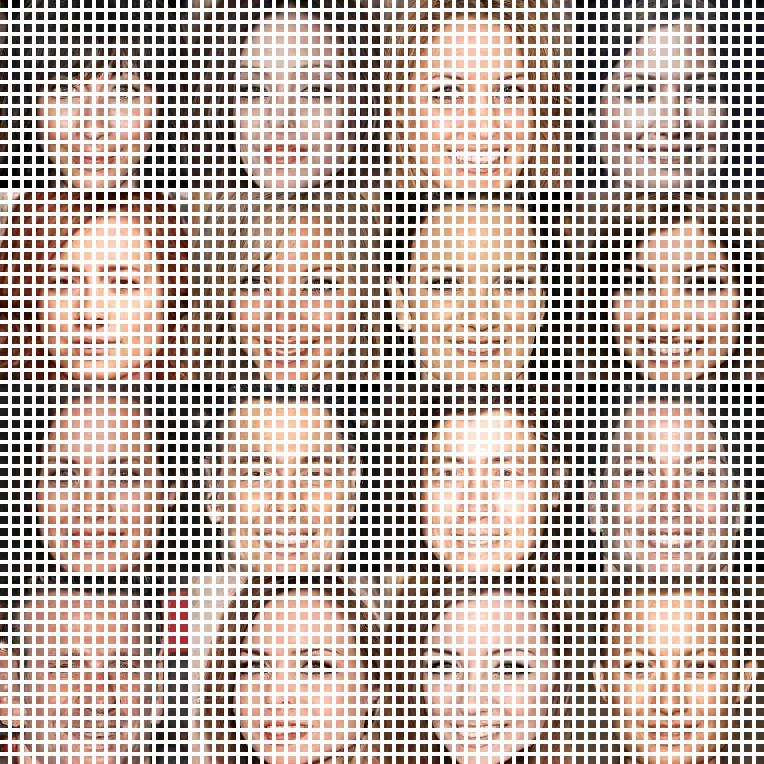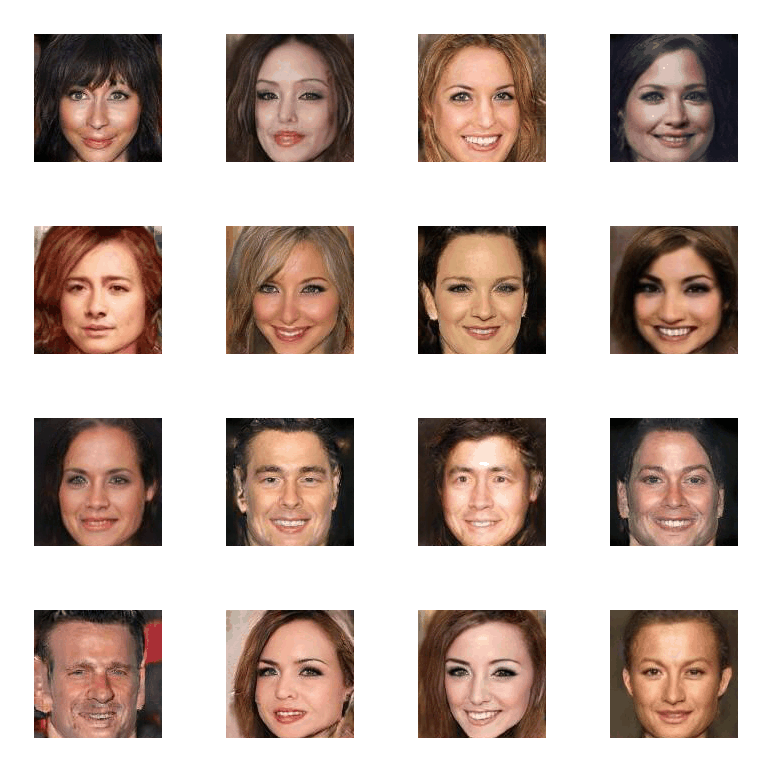
|
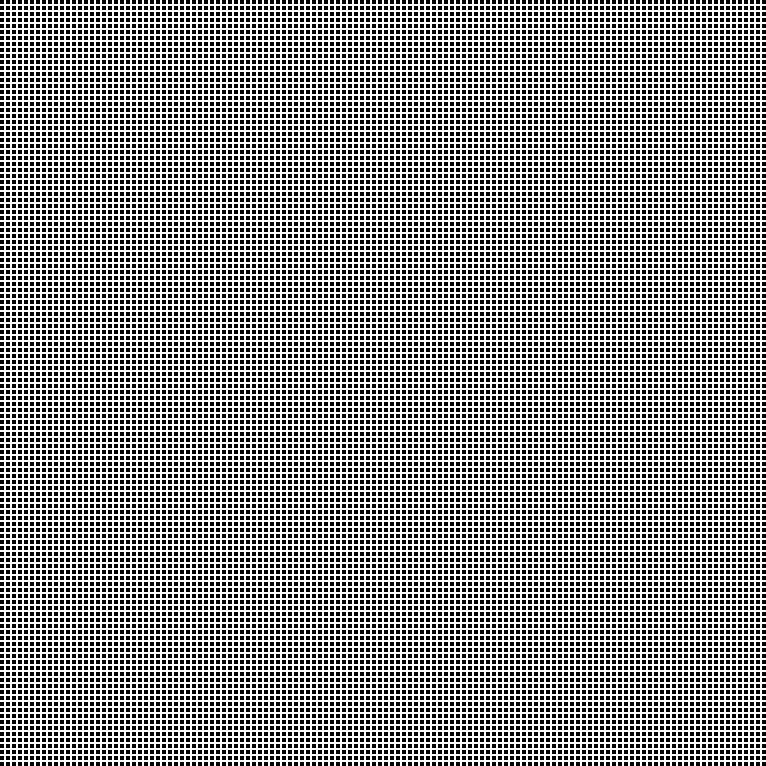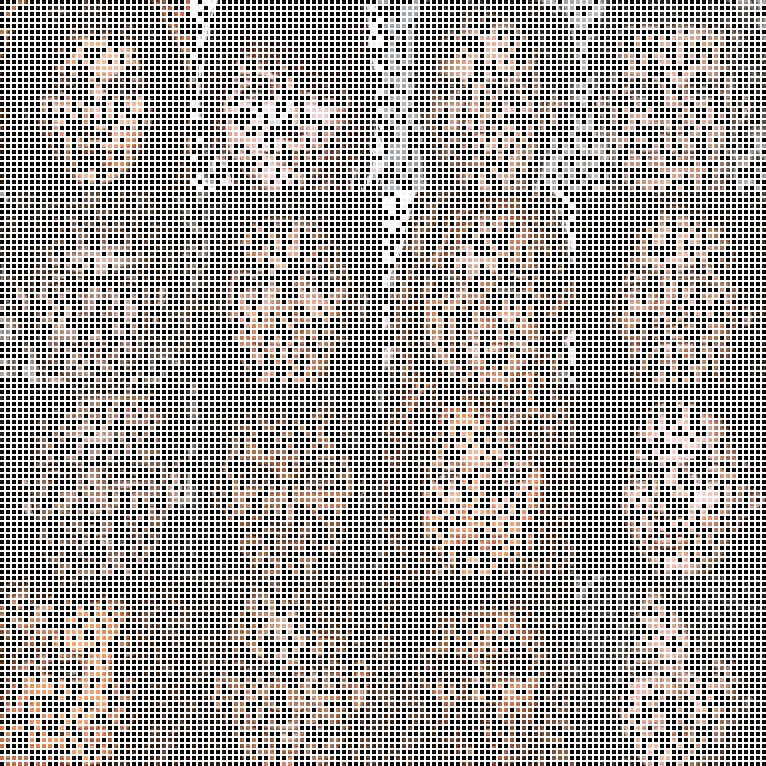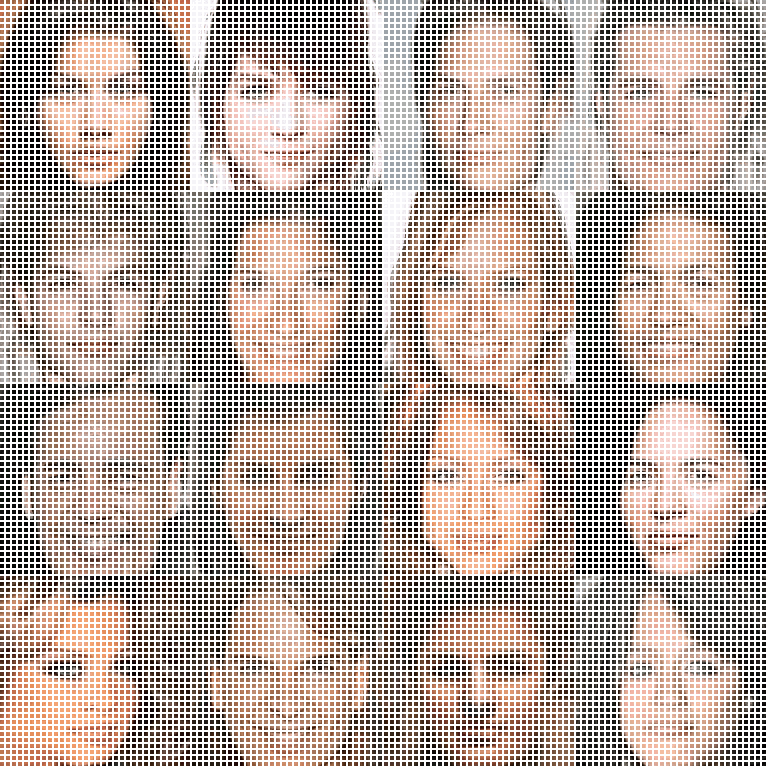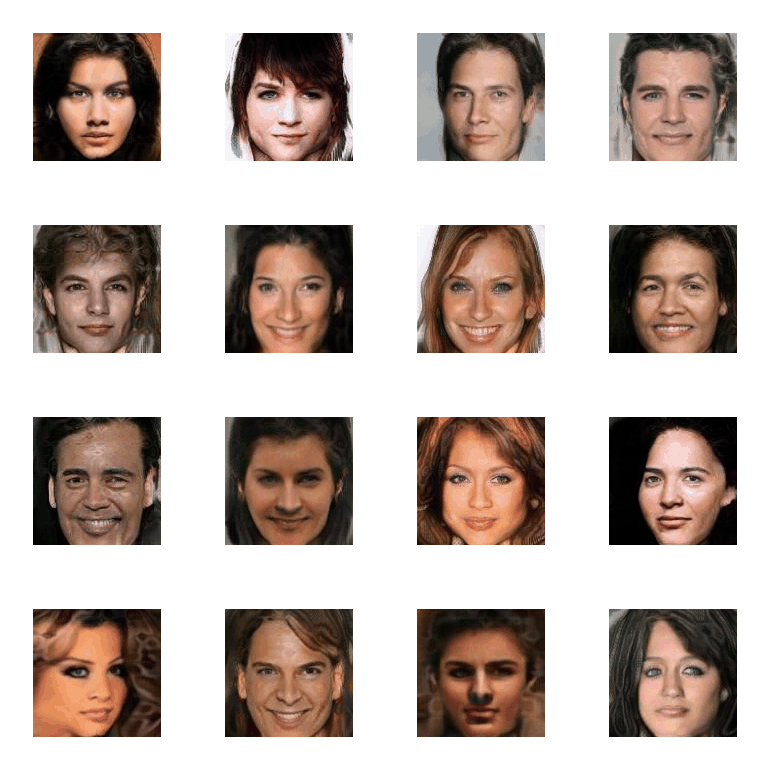
|
▲ In different patch size setups, COCO-GAN parallelly generates small patches. The generated small patches are directly concatenate together to form a high-quality image. In the right-most example, we can still generate high-quality images even with extremely tiny 4x4 pixels patches.
Abstract
Humans can only interact with part of the surrounding environment due to biological restrictions. Therefore, we learn to reason the spatial relationships across a series of observations to piece together the surrounding environment. Inspired by such behavior and the fact that machines also have computational constraints, we propose COnditional COordinate GAN (COCO-GAN) of which the generator generates images by parts based on their spatial coordinates as the condition. On the other hand, the discriminator learns to justify realism across multiple assembled patches by global coherence, local appearance, and edge-crossing continuity. Despite the full images are never generated during training, we show that COCO-GAN can produce state-of-the-art-quality full images during inference. We further demonstrate a variety of novel applications enabled by teaching the network to be aware of coordinates. First, we perform extrapolation to the learned coordinate manifold and generate off-the-boundary patches. Combining with the originally generated full image, COCO-GAN can produce images that are larger than training samples, which we called "beyond-boundary generation". We then showcase panorama generation within a cylindrical coordinate system that inherently preserves horizontally cyclic topology. On the computation side, COCO-GAN has a built-in divide-and-conquer paradigm that reduces memory requisition during training and inference, provides high-parallelism, and can generate parts of images on-demand.

Paper
ICCV (Oral), 2019.
Code
Citation
@inproceedings{lin2019cocogan,
author={Lin, Chieh Hubert and Chang, Chia{-}Che and Chen, Yu{-}Sheng and Juan, Da{-}Cheng and Wei, Wei and Chen, Hwann{-}Tzong},
title={{COCO-GAN:} Generation by Parts via Conditional Coordinating},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2019},
}
Overview of the Method
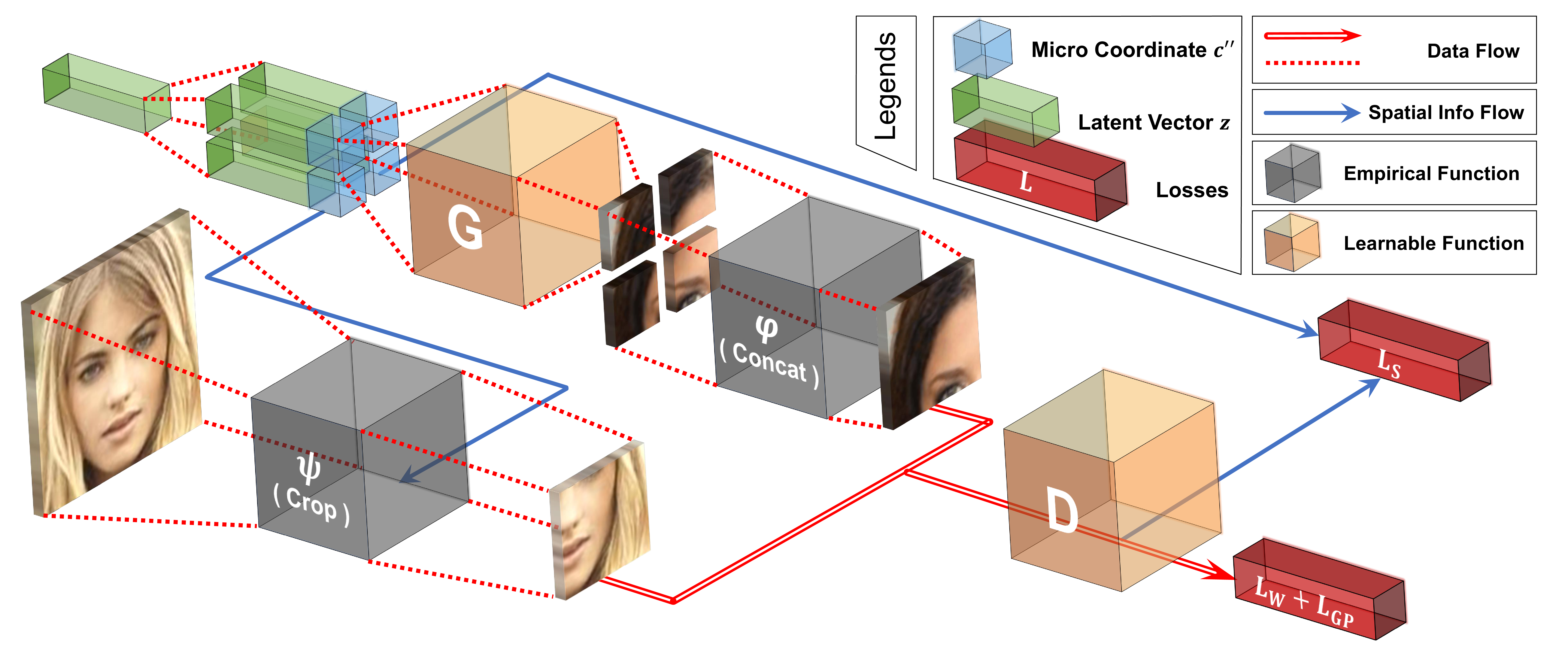
For the COCO-GAN training, the latent vectors are duplicated multiple times, concatenated with micro coordinates, and feed to the generator to generate micro patches. Then we concatenate multiple micro patches to form a larger macro patch. The discriminator learns to discriminate between real and fake macro patches and an auxiliary task predicting the coordinate of the macro patch. Notice that none of the models requires full images during training.
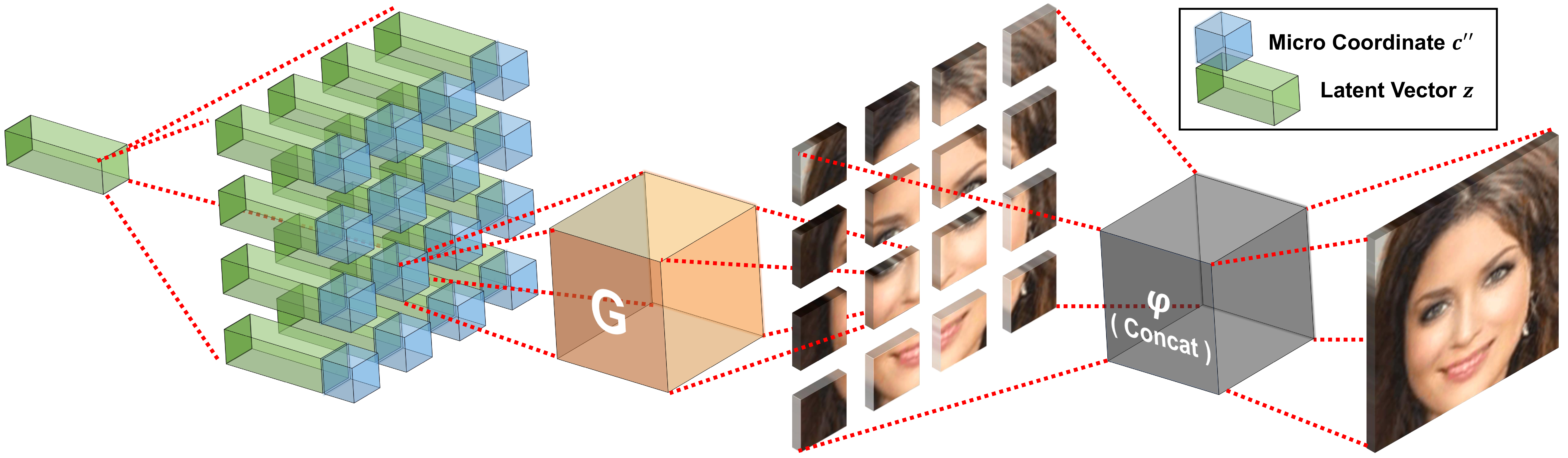
During the testing phase, the micro patches generated by the generator are directly combined into a full image as the final output. Still, none of the models requires full images. Furthermore, the generated images are high-quality without any post-processing in addition to a simple concatenation.
Applications: Beyond-Boundary Image Generation

COCO-GAN can generate additional contents by extrapolating the learned coordinate manifold. More specifically, with a fixed latent vector, we extrapolates the coordinate condition beyond the training coordinates distribution. We show that COCO-GAN generates high-quality 384x384 images: the original size is 256x256, with each direction being extended by one micro patch (64x64 pixels), resulting a size of 384x384. Note that the model is in fact trained on 256x256 images.
Applications: Patch-Guided Image Generation
Some prior works [1][2][3][4] have shown that we can train a bijective function within the discriminator that maps each image to a corresponding latent vector. Such a component becomes interesting in COCO-GAN setting, since the discriminator of COCO-GAN only consumes macro patches. As a result, COCO-GAN can estimate a latent vector with only a part of an image, then generates a full image that locally retains some characteristics of the given macro patch, while still globally coherent.
Applications: Panorama Generation

▲ By applying a cylindrical coordinate system, the panorama generated by COCO-GAN is natively horizontally cyclic.
Acknowledgement
We sincerely thank David Berthelot and Mong-li Shih for the insightful suggestions and advice. We are grateful to the National Center for High-performance Computing for computer time and facilities. Hwann-Tzong Chen was supported in part by MOST grants 107-2634-F-001-002 and 107-2218-E-007-047.
References
[1]
X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, P. Abbeel. "Infogan: Interpretable representation learning by information maximizing generative adversarial nets", in NIPS 2016.
[2]
V. Dumoulin, I. Belghazi, B. Poole, A. Lamb, M. Arjovsky, O. Mastropietro, A. Courville. "Adversarially Learned Inference", in ICLR 2017.
[3]
J. Donahue, P. Krähenbühl, T. Darrell. "Adversarial Feature Learning", in ICLR 2017.
[4]
C.-C. Chang, C. H. Lin, C.-R. Lee, D.-C. Juan, W. Wei, H.-T. Chen. "Escaping from Collapsing Modes in a Constrained Space" in ECCV 2018.
