InstaNAS: Instance-aware Neural Architecture Search
AAAI'20 | ICML'19 AutoML Workshop
An-Chieh Cheng* Chieh Hubert Lin* Da-Cheng Juan Wei Wei Min Sun
National Tsing Hua University Google AI
Paper (Arxiv) | Code (to be released soon)
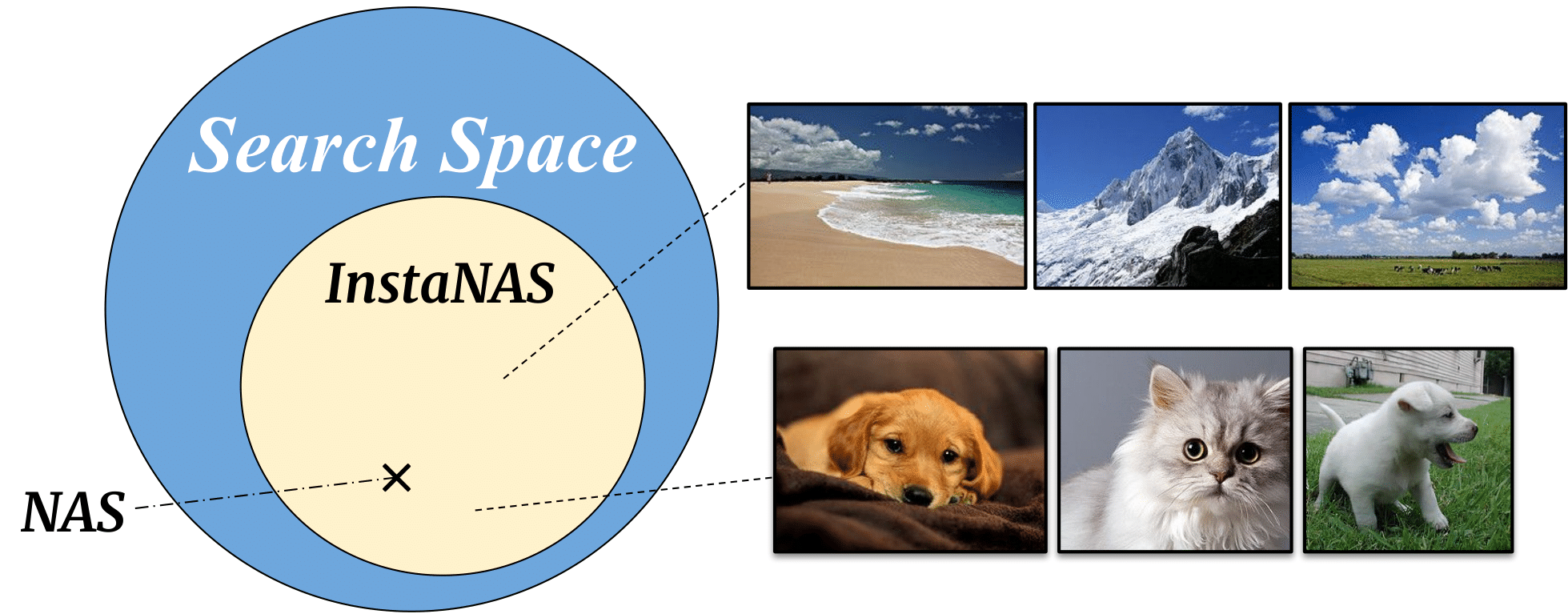
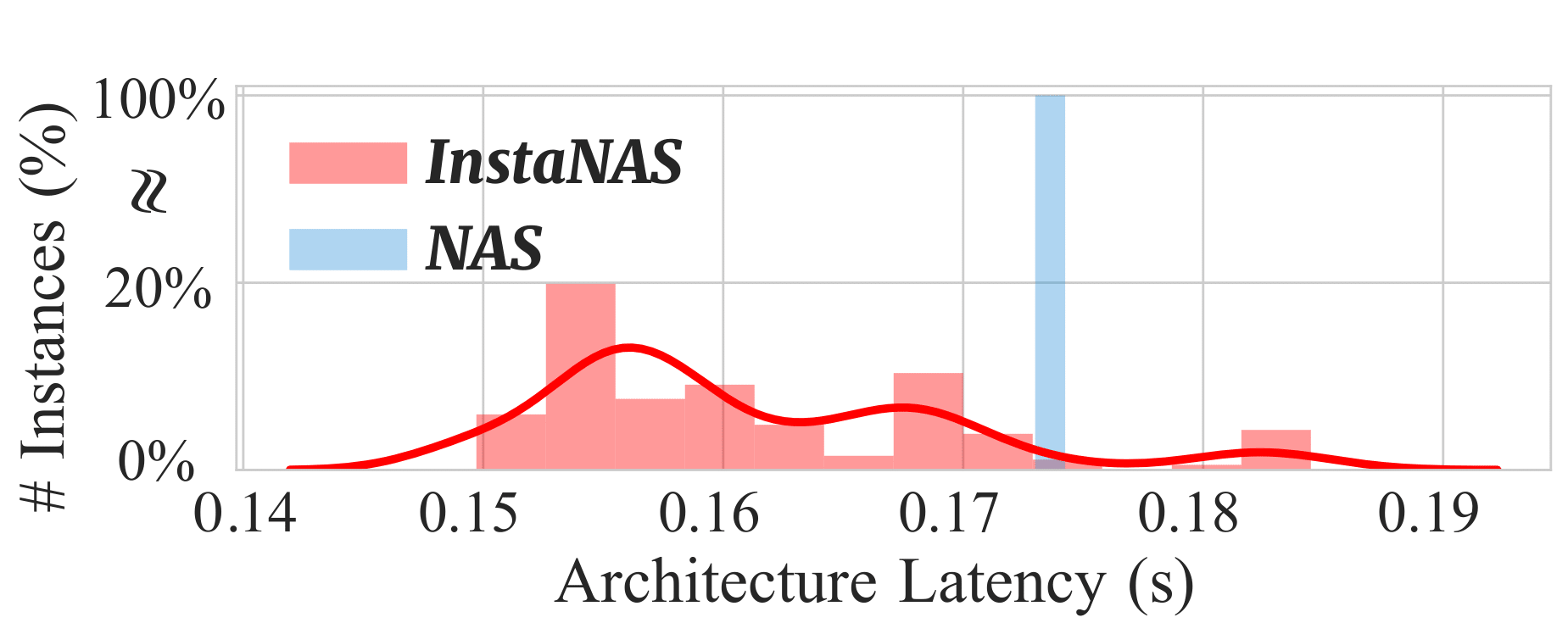
▲ The concept of InstaNAS is to search for a
Abstract
Neural Architecture Search (NAS) aims at finding one “single” architecture that achieves the best accuracy for a given task such as image recognition. In this paper, we study the instance-level variation, and demonstrate that instance-awareness is an important yet currently missing component of NAS. Based on this observation, we propose InstaNAS for searching toward instance-level architectures; the controller is trained to search and form a “distribution of architectures” instead of a single final architecture. Then during the inference phase, the controller selects an architecture from the distribution, tailored for each unseen image to achieve both high accuracy and short latency. The experimental results show that InstaNAS reduces the inference latency without compromising classification accuracy. On average, InstaNAS achieves 48.9% latency reduction on CIFAR-10 and 40.2% latency reduction on CIFAR-100 with respect to MobileNetV2 architecture.
Paper
arxiv, 2019.
Code
Citation
@article{anchieh2018instanas,
title={InstaNAS: Instance-aware Neural Architecture Search},
author={Cheng, An-Chieh* and Lin, Chieh Hubert* and Juan, Da-Cheng and Wei, Wei and Sun, Min},
booktitle={Thirty-Fourth AAAI Conference on Artificial Intelligence},
year={2020}
}
Overview of the Method
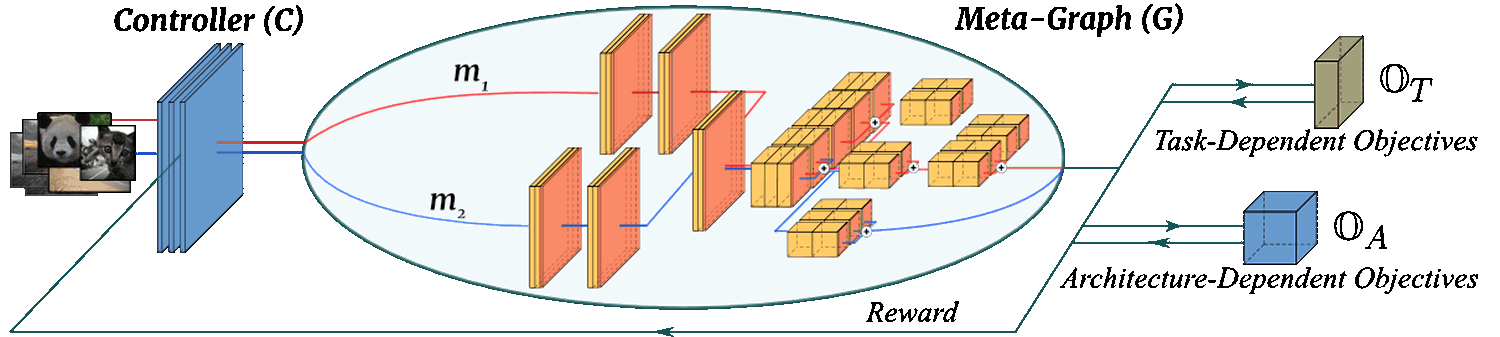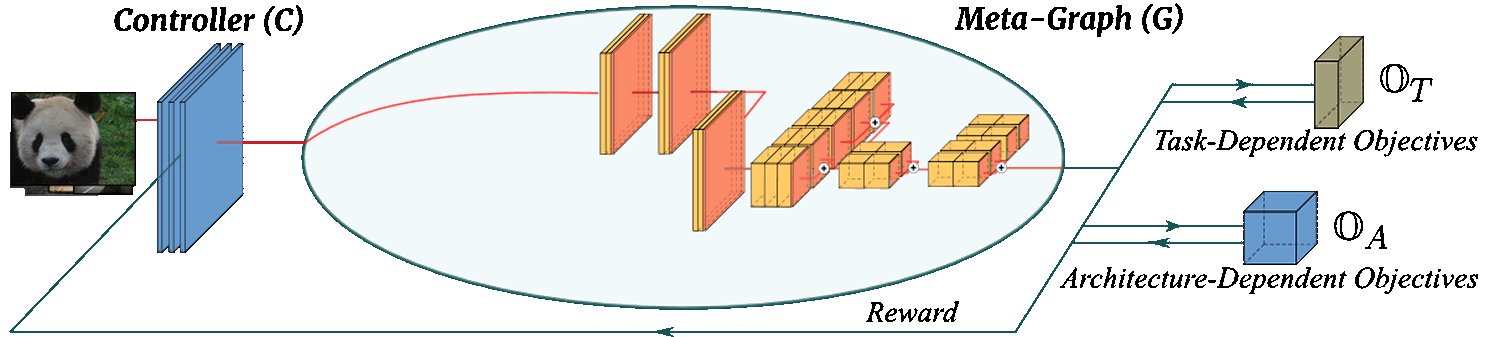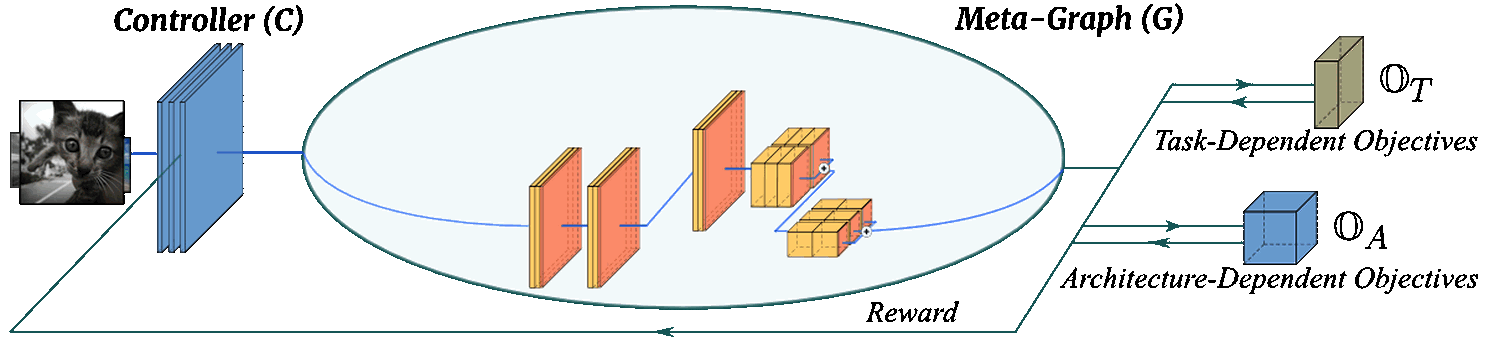
InstaNAS is a multi-objective (OT and OA, we target accuracy and latency in our experiments) framework consists of two major componenets: a controller and a meta-graph:
The Instance-aware Controller -- Conventional NAS controller is only responsible for RL sampling process, thus only takes effect during the search phase. On the other hand, the controller of InstaNAS is instance-aware and plays an important role for both search and inference phase. In both stages, the InstaNAS controller takes the input sample and accordingly designs an architecture for the input sample. The controller is trained with policy gradient while considering multiple objectives. As a result, the controller tries to explore and find the best trade-off between the objectives in an instance-wise manner.
The One-Shot Meta-Graph -- Many recent NAS frameworks [1][2][3] share the similar concept of constructing weight-sharing meta-graph. InstaNAS inherits the same line of research. However, different to existing works, InstaNAS controller training insists random exploration within the meta-graph. To resolve this problem, we propose to utilize the recently proposed one-shot architecture search [2] to pre-train our meta-graph. With such a pre-training strategy, any randomly sampled architecture becomes a valid architecture with decent accuracy, thus the controller can receive stable and correct reward to learn with policy gradient.
Live Demo (Architectures Established by InstaNAS Controller)
We deployed one of the InstaNAS controller trained on ImageNet on your browser (with onnx.js)! You may select some of the ImageNet testing samples (each row shares the same architecture) below and see the architectures selected by the InstaNAS controller. You may also upload your own testing samples. Enjoy!
(Note) If you don't see any image displayed on the left panel, possibly your AdBlock blocks the onnx.js scripts or onnx.js does not support your device. Please close AdBlock or try another device.
Try with your sample!

Experiment: Better Accuracy-Latency Trade-off Frontier
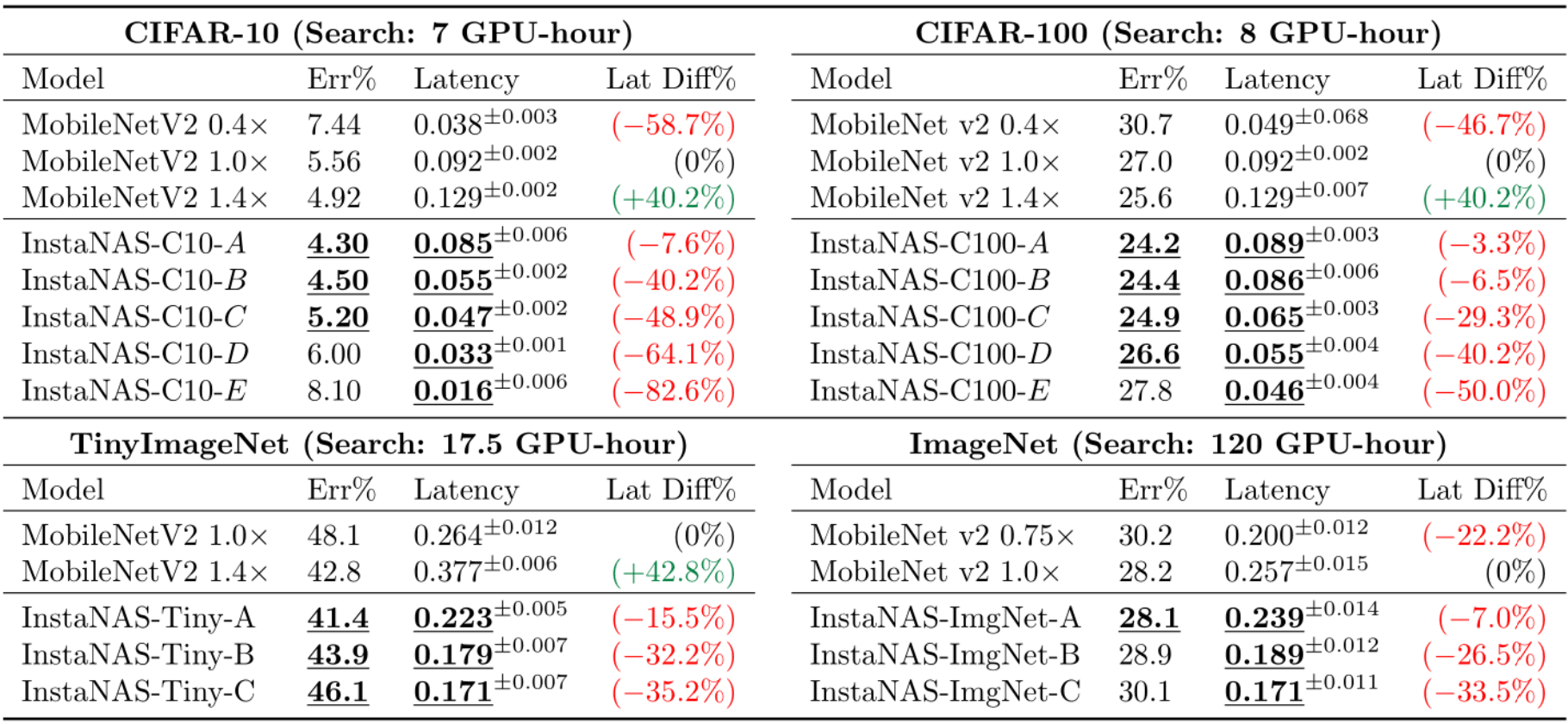
▲ We highlight values that are better than MobileNetV2 1.0x since we conduct the experiments in a MobileNetV2-1.0x-based search space.
Performance gain: InstaNAS consistently improves MobileNetV2 accuracy-latency trade-off frontier on a variety of datasets. InstaNAS achieves up to 48.9% latency reduction without accuracy reduction, 82.6% latency reduction if moderate accuracy drop is acceptable, and accuracy improvement in some datasets.
Trade-off frontier in a single search: All InstaNAS variants (InstaNAS A-E or A-C) in each sub-table are obtained in a single search. InstaNAS adopts a dynamic reward design. Such a design makes the controller in each epoch stands for different level of trade-off between latency and accuracy.
Experiment: OutPerforms Other Baselines
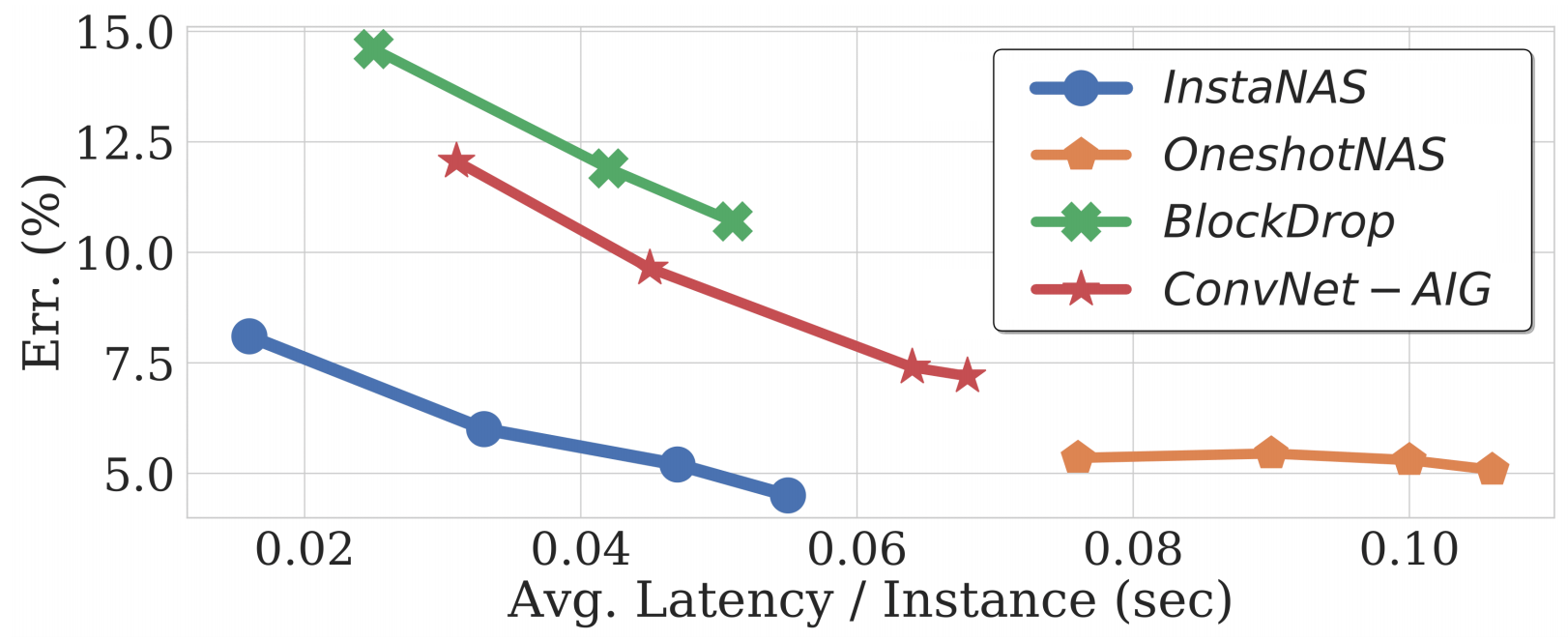
We also compared with multiple other baselines on CIFAR-10, including OneshotNAS [2] (which we used in our pre-training phase) and conditional computation methods (BlockDrop [4] and ConvNet-AIG [5]). The results suggest InstaNAS outperforms these methods with a large margin.
Visualization: Computation-by-Difficulty Similar to Human Perception

We visualize how InstaNAS handle the high-intra-class variance of ImageNet samples and select architectures according to the difficulty of samples. Hard samples tend to be assigned with more sophisticated architecutures. The estimated difficulty interestingly matches human perception (e.g., cluttered background, high intra-class variation, illumination conditions).
Visualization: The Distribution of Architectures
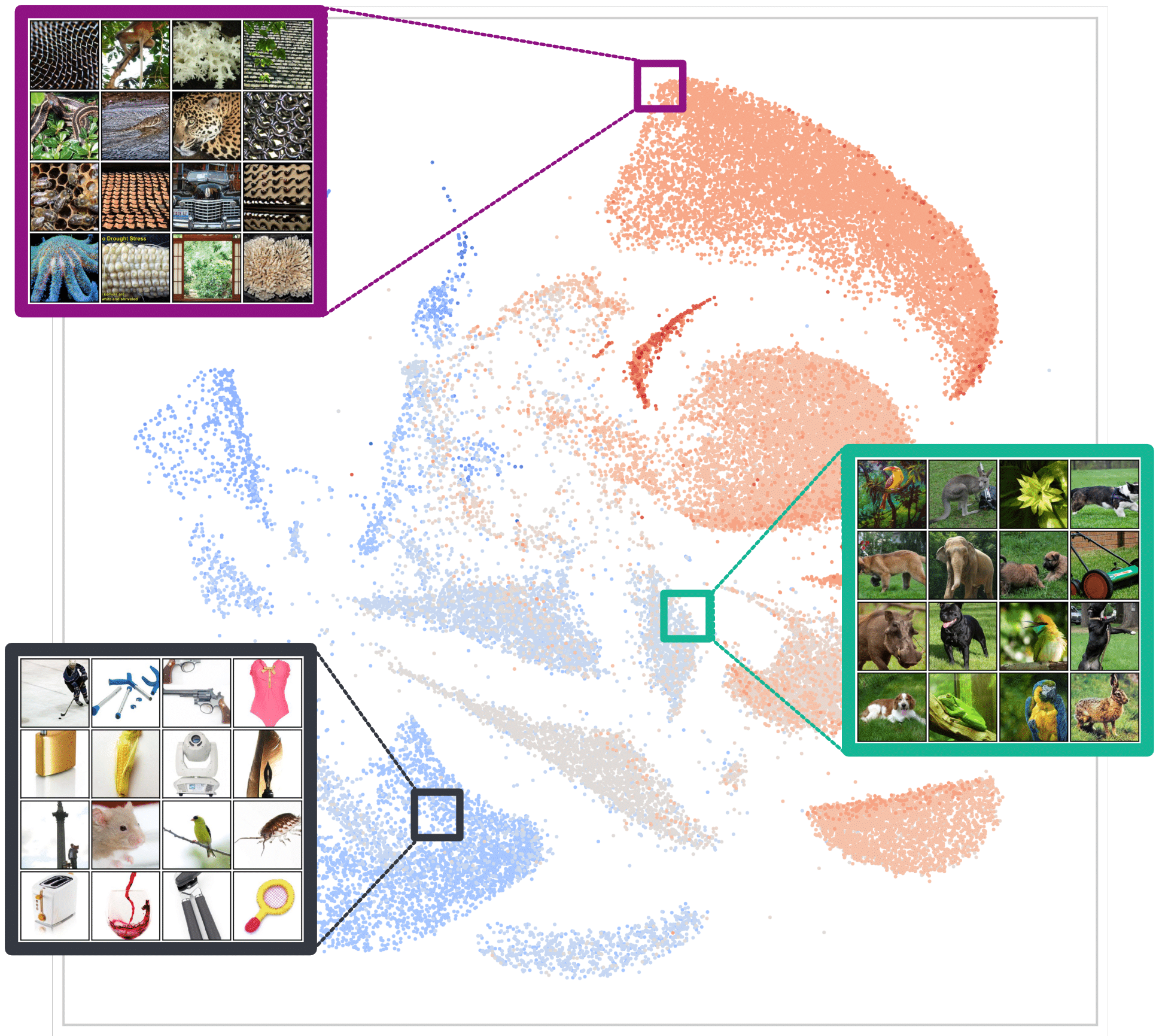
▲ The distribution of architectures predicted by the controller on ImageNet training set. The color indicates the latency of architecture. Red dots indicate slower architectures and blue points indicate faster architectures
We collect all architectures (in probability form) predicted by InstaNAS controller and project to 2D space with UMAP [6]. We observe the controller can distinguish the difficulty of samples and assign architectures with corresponding complexity. Furthermore, the clear clusters indicate the distance between distributions is significant and the controller has definite policy to identify certain features of each input instance.
References
[1]
H. Pham, M. Guan, B. Zoph, Q. Le, J. Dean. "Efficient Neural Architecture Search via Parameter Sharing" in ICML 2018.
[2]
G. Bender, P.-J. Kindermans, B. Zoph, V. Vasudevan, Q. Le. "Escaping from Collapsing Modes in a Constrained Space" in ICML 2018.
[3]
H. Liu, K. Simonyan, Y. Yang. "DARTS: Differentiable Architecture Search " in ICLR 2019.
[4]
Z. Wu, T. Nagarajan, A. Kumar, S. Rennie, L. S. Davis, K. Grauman, R. Feris. "BlockDrop: Dynamic Inference Paths in Residual Networks" in CVPR 2018.
[5]
A. Veit, S. Belongie. "Convolutional Networks with Adaptive Inference Graphs" in ECCV 2018.
[6]
L. McInnes, J. Healy, N. Saul, L. Grossberger. "UMAP: Uniform Manifold Approximation and Projection" in "The Journal of Open Source Software" and Arxiv.
